Openarz - kodowanie i analiza openów w minutę
28/05/2026

Wiele miesięcy prac zespołu badaczy i programistów przyniosło efekt w postaci aplikacji Openarz, której możliwości wykraczają poza automatyczną kategoryzację tekstu.
Sztuczna inteligencja zaczyna odgrywać rolę nie tylko w tworzeniu treści czy automatyzacji pracy, ale również w badaniach rynku i opinii. Jednym z niezwykle czasochłonnych etapów pracy badawczej, wymagającym dotychczas zaangażowania nieraz kilku badaczy lub analityków, jest proces kategoryzacji (kodowania) swobodnych wypowiedzi respondentów w pytaniach otwartych.
W badaniach ankietowych respondenci często odpowiadają własnymi słowami na tego typu pytania. Mogą one być sformułowane np. “jakie instytucje finansowe Pan/Pani zna?” albo “jakie emocje budzi w Panu/Pani dana kampania społeczna?”.
Dla firmy badawczej oznacza to konieczność przyporządkowania każdej odpowiedzi do kategorii z klucza kodowego. Przykładowo, jeśli respondent wpisze „ACME”, „ACME SA”, „bank ACME” albo „Ejkmi”, człowiek musi zdecydować, czy chodzi o tę samą instytucję, czy o różne podmioty. Takie zadanie wymaga doświadczenia, inwestycji w czas pracy, a niekiedy zaangażowania wielu koderów, aby móc rozstrzygać niejednoznacznie zakodowane odpowiedzi. Mimo, że pytania otwarte oraz udzielane odpowiedzi brzmią naturalnie, to z analitycznego punktu widzenia stanowią niemałe wyzwanie. Nieraz odpowiedzi mające podobne identyczne lub podobne znaczenie mogą być zapisane na tysiąc sposobów. Mogą zawierać różnego rodzaju błędy, literówki, skróty, zapisy fonetyczne czy inne określenia, które przed analizą powinny zostać wychwycone przez badacza.
Zautomatyzowaliśmy tę część pracy badaczy przy użyciu dużych modeli językowych (LLM).
Zobaczmy, jak to działa.
W początkowej fazie do modelu trafia duża ilość surowych odpowiedzi respondentów. Pierwszym zadaniem modelu jest stworzenie tzw. klucza kodowego, czyli identyfikacja najważniejszych grup odpowiedzi. Klucz ten może być wygenerowany na bazie parametrów podanych przez analityka lub wczytany z przygotowanego wcześniej pliku.
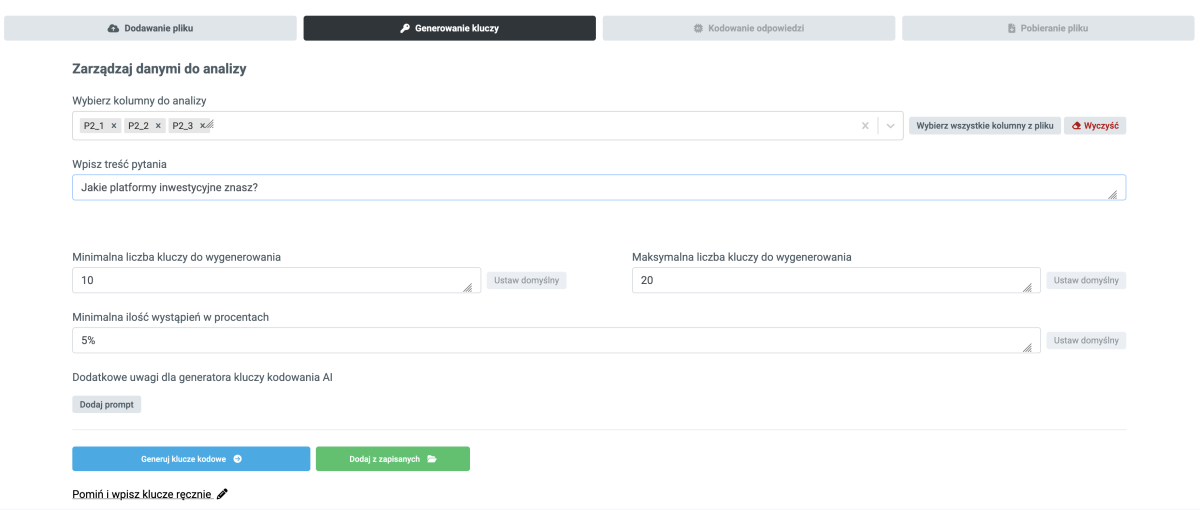
Model generując kategorie proponuje ich nazwy. Jeśli ankietowani wymieniają banki, może on wygenerować kategorie odpowiadające konkretnym instytucjom finansowym, ale również bardziej ogólne klasy, takie jak „banki internetowe”, “polskie banki”, „parabanki” itd. Co ważne, badacz może zastrzec, aby model nie ulegał pokusie halucynacji i wymusić, aby w niejasnych sytuacjach pojawił się kod „odpowiedź niejednoznaczna”.
Istotną cechą systemu, który odróżnia go od istniejących na rynku, jest jego elastyczność. W przeciwieństwie do innych narzędzi, analiza nie musi ograniczać się wyłącznie do oryginalnego pytania z kwestionariusza. Analityk może w dowolnym momencie sformułować dodatkowe instrukcje lub ukierunkować proces klasyfikacji na wybrany aspekt odpowiedzi. W praktyce oznacza to możliwość tworzenia zarówno szczegółowych kategorii tematycznych, jak i bardzo ogólnych klasyfikacji — na przykład ograniczonych wyłącznie do sentymentu wypowiedzi (pozytywny, negatywny, neutralny).
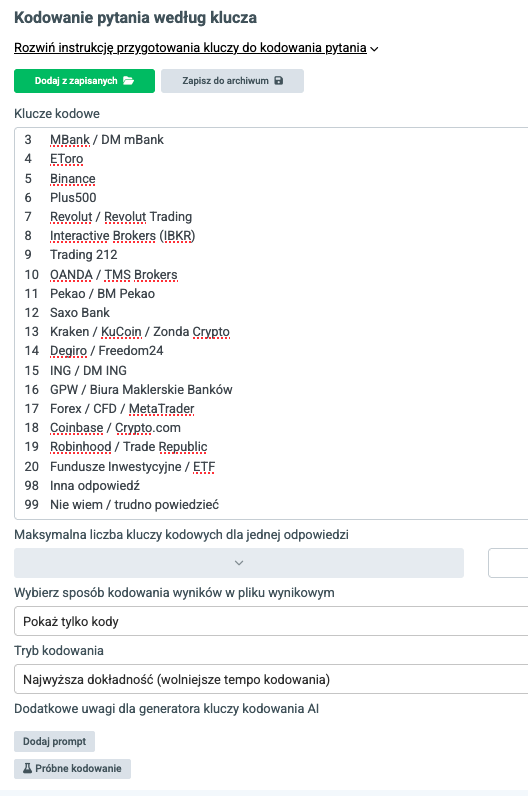
W drugim etapie analityk ocenia pracę modelu. Jeśli uzna, że wskazana przez niego liczba kategorii nie prowadzi do sensownego kodowania, może wskazać inną liczbę i powtórnie zlecić poszukiwanie optymalnego zbioru kategorii.
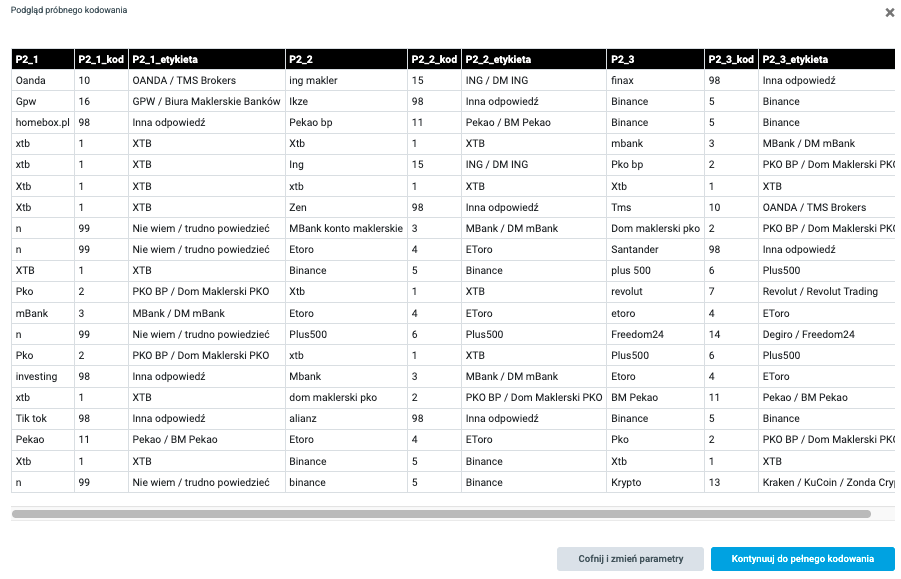
Po akceptacji klucza przez analityka Openarz otrzymuje listę kategorii i ma przypisać każdemu respondentowi odpowiednie kody klasyfikacyjne. Następnie analityk może także sprawdzić próbkę przyporządkowania przed zakodowaniem wszystkich wierszy.
Główny specjalista AI/ML w SW Research prof. dr hab. Krzysztof Stencel z Instytutu Matematyki Uniwersytetu Warszawskiego wyjaśnia:
W pierwszym etapie kodowania model wykonuje proces zbliżony do grupowania semantycznego. Odpowiedzi tekstowe w modelu są wewnętrznie interpretowane jako wielowymiarowe reprezentacje matematyczne, często określane jako osadzenia (ang. embeddings). W takim ujęciu podobne znaczeniowo odpowiedzi znajdują się „blisko siebie” w przestrzeni wektorowej. Dzięki temu AI potrafi zauważyć, że odpowiedzi „ACME”, „ACME SA”, „bank internetowy ACME” albo “konto w ACME” odnoszą się do tego samego pojęcia, mimo że zapisano je różnymi słowami. Model identyfikuje podobieństwa semantyczne zamiast polegać wyłącznie na identyczności tekstu.
Kiedy użytkownik określa liczbę kategorii (np. 10), model stara się podzielić odpowiedzi na 10 względnie spójnych grup semantycznych. Nie musi to być klasyczny algorytm analizy skupień (ang. clustering) znany z uczenia maszynowego, taki jak k-średnich (ang. k-means) lub DBSCAN ale efekt jest podobny: model tworzy reprezentatywne klasy odpowiadające dominującym tematom występującym w danych.
Następnie Openarz generuje etykiety kategorii. To etap szczególnie interesujący z punktu widzenia badań rynku, ponieważ model nie tylko grupuje odpowiedzi, ale również interpretuje ich znaczenie i proponuje nazwy zrozumiałe dla człowieka a jednocześnie pasujące do kontekstu pytania.
W drugim etapie Openarz działa bardziej jak klasyfikator. Otrzymuje wcześniej ustalony zestaw kategorii i dla każdej nowej odpowiedzi ocenia, do której klasy najlepiej pasuje dany tekst. Model wykorzystuje przy tym zarówno podobieństwo semantyczne, jak i wiedzę kontekstową zdobytą podczas treningu. Można przypuszczać, że Openarz wykonuje tu wewnętrznie coś podobnego do bezprzykładowego (ang. zero-shot) lub kilkuprzykładowego (ang. few-shot) uczenia klasyfikatora.
Warto pamiętać, że opisane mechanizmy są w dużej mierze rekonstrukcją sposobu działania współczesnych modeli językowych, a nie oficjalnym opisem ich wewnętrznych algorytmów. Firmy rozwijające takie systemy nie ujawniają pełnej architektury modeli ani dokładnego procesu podejmowania decyzji. Z perspektywy informatyka widać jednak wyraźnie, że współczesne LLM-y bardzo skutecznie łączą analizę podobieństwa semantycznego z uogólnianiem kontekstowym. Dzięki temu potrafią wykonywać zadania klasyfikacyjne i interpretacyjne bez konieczności manualnego definiowania reguł, co jeszcze kilka lat temu było znacznie trudniejsze do osiągnięcia.
Dotychczas automatyzacja badań rynku koncentrowała się głównie na analizie danych liczbowych zakodowanych przez skrypt CAWI, CATI lub CAPI. Duże modele językowe po raz pierwszy umożliwiają jednak efektywne przetwarzanie ogromnych ilości nieustrukturyzowanego tekstu.
Warto jednak podkreślić, że rozwiązanie SW Research znacznie wykracza poza proste wykorzystanie ogólnodostępnych dużych modeli językowych (np. chat GPT, Gemini czy Claude) poprzez manualne kopiowanie i wklejanie odpowiedzi respondentów do konsoli. System został zaprojektowany jako dedykowane środowisko analityczne, które umożliwia iteracyjne tworzenie schematów kodowania, kontrolę jakości i szczegółowości kategorii, rekategoryzację danych według ustalonego schematu oraz zachowanie spójności procesu analitycznego między kolejnymi badaniami. To ostatnie jest szczególnie przydatne we wszelkiego rodzaju badaniach trackingowych, testach pre-post oraz czy badaniach podłużnych. Dzięki temu możliwe jest prowadzenie analiz w sposób bardziej powtarzalny, transparentny i metodologicznie kontrolowany niż w przypadku doraźnego wykorzystania modeli AI.
Eksperci podkreślają jednak, że kluczowe pozostaje zachowanie kontroli metodologicznej:
Najskuteczniejsze podejście prawdopodobnie będzie opierać się na współpracy człowieka i AI — gdzie sztuczna inteligencja odpowiada za skalę i szybkość działania, a eksperci za interpretację i nadzór jakościowy. Dla branży badawczej może to oznaczać początek nowej epoki, w której analiza języka naturalnego stanie się równie zautomatyzowana jak tradycyjna analiza statystyczna - wyjaśnia Przemek Wesołowski, CEO SW Research
Proces, który wcześniej mógł zajmować dni a nawet tygodnie, może zostać wykonany w ciągu niecałej godziny. Istotna jest również skalowalność nowego rozwiązania. Współczesne badania coraz częściej obejmują dziesiątki tysięcy respondentów, a analiza odpowiedzi tekstowych była jednym z głównych ograniczeń prowadzenia badań w dużej skali wykorzystujących pełnie możliwości pytań otwartych.
Piotr Zimolzak, wiceprezes SW Research dodaje:
Modele językowe umożliwiają obsługę dużych wolumenów danych bez konieczności proporcjonalnego zwiększania liczby analityków. Jednak zyskają na tym nie tylko badania ilościowe na dużych próbach respondentów - w końcu ogromne ilości tekstu spotykamy również w badaniach jakościowych czy w analizie treści, w tym desk research. Uważamy, że nowy model kodowania znacząco zmieni sposób prowadzenia badań opinii społecznej, analiz konsumenckich czy monitoringu marek. Firmy badawcze zyskują możliwość szybszego reagowania na zmiany rynkowe oraz głębszego zrozumienia języka i emocji respondentów. Jednocześnie rozwiązanie nie eliminuje całkowicie roli człowieka. Badacze nadal muszą kontrolować jakość wygenerowanych kategorii, oceniać sensowność klasyfikacji oraz interpretować wyniki. Sztuczna inteligencja staje się raczej zaawansowanym narzędziem wspomagającym ekspertów niż pełnym zastępstwem dla ich pracy
Oficjalnie - Openarz będzie dostępny od 1 września 2026 roku w planie Enterprise Ankieteo.
Umożliwi kodowanie pytań z poziomu Ankieteo lub wgrywanych baz danych (SPSS lub Excel).
Koszt zakodowania jednego pytania zaczyna się od 1 kredytu = 1 PLN. Każdy posiadacz planu Enterprise otrzyma 100 darmowych kredytów.
Dzięki niewielkiej inwestycji zaoszczędzisz godziny żmudnej pracy Twojej lub Twojego zespołu.
